Redis 数据结构
文章目录
Redis 底层数据结构
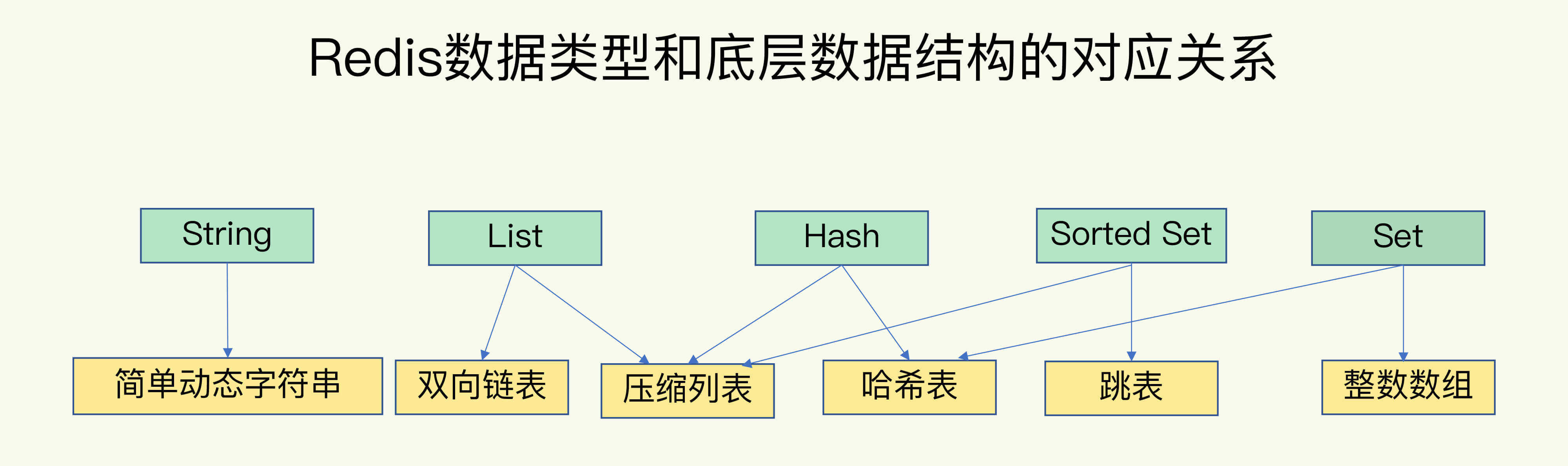
哈希表
全局哈希表
- Redis 使用一个哈希表来保存所有键值对。一个哈希表,其实就是一个数组,数组的每个元素称为一个哈希桶。
- 哈希桶中的元素保存的并不是值本身,而是指向具体值的指针。
- 哈希表可以用 O(1) 的时间复杂度来快速查找到键值对,只要计算键的哈希值,就能找到它所对应的哈希桶的位置
哈希冲突
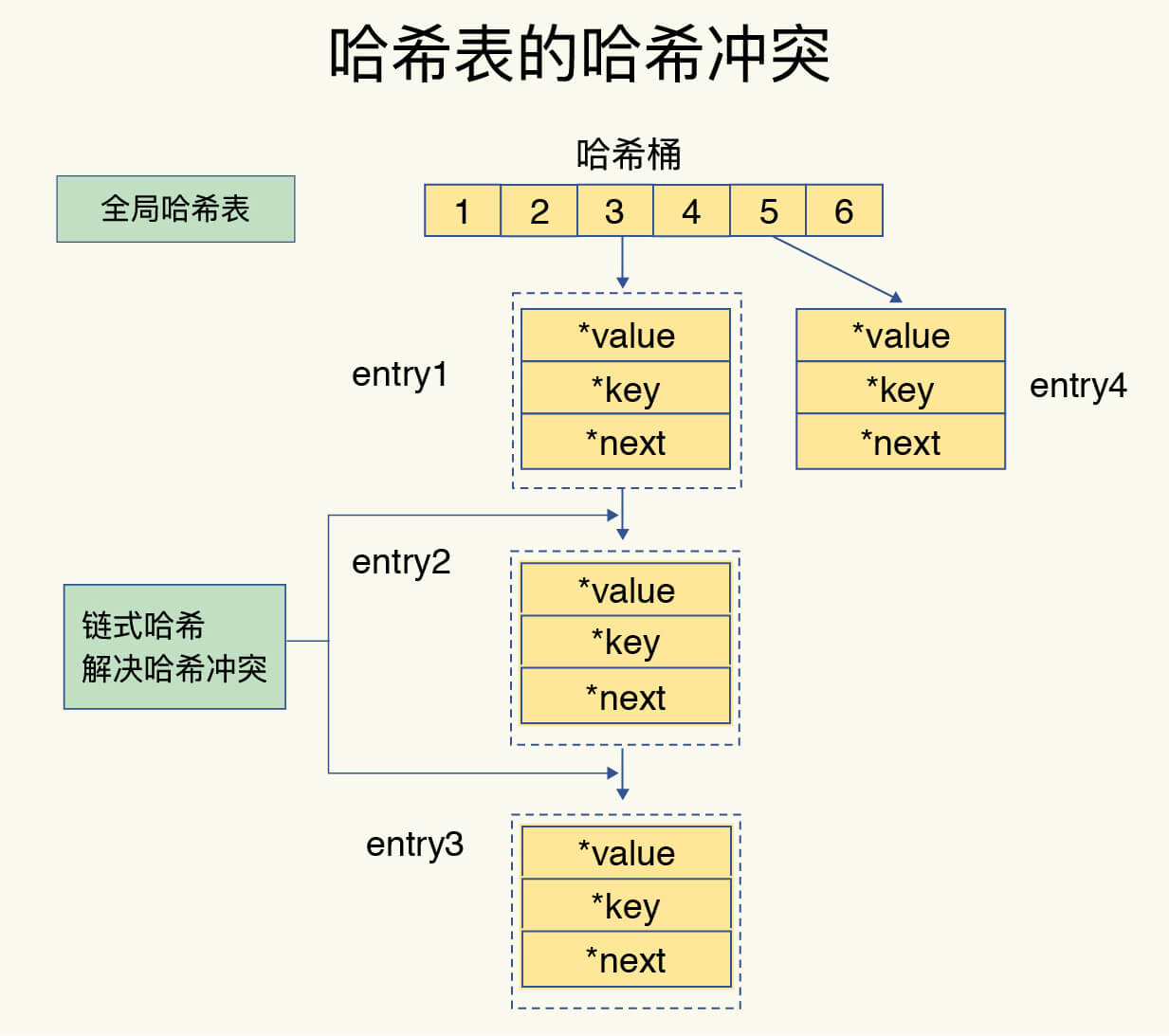
- 随着哈希表写入更多数据,哈希冲突(多个 key 的哈希值对应到同一个哈希桶中)会越来越多。
- Redis 解决哈希冲突的方式是 链式哈希,同一个哈希桶中的多个元素用一个链表来保存,它们之间依次用指针连接。
- 如图所示,entry1、entry2 和 entry3 都需要保存在哈希桶 3 中,导致了哈希冲突。此时,entry1 元素会通过一个*next指针指向 entry2,同样,entry2 也会通过*next指针指向 entry3。
rehash
- 哈希冲突链上的元素只能通过指针逐一查找再操作。随着哈希冲突的增多,查询耗时会越来越长,为了解决这个问题,Reids 会对表进行 rehash 操作
- Redis 默认使用了两个全局哈希表:哈希表 1 和哈希表 2。一开始插入数据时,默认使用哈希表 1,此时的哈希表 2 并没有被分配空间。随着数据逐步增多,Redis 开始执行 rehash
- 给哈希表 2 分配更大的空间,例如是当前哈希表 1 大小的两倍;
- 把哈希表 1 中的数据重新映射并拷贝到哈希表 2 中;
- 需拷贝数据量过大时,一次性拷贝会导致线程阻塞,所以采用渐进式 refresh
- 拷贝时,redis不会一次性拷贝,而是仍正常处理客户端请求,每处理了一个请求,就从哈希表 1 中的第一个索引位置开始,顺带着将这个索引位置上的所有 entries 拷贝到哈希表 2 中
- 释放哈希表 1 的空间,哈希表 1 留作下一次 rehash 扩容备用。
整数数组和双向链表
- 它们的操作特征都是顺序读写,也就是通过数组下标或者链表的指针逐个元素访问,操作复杂度基本是 O(N),操作效率比较低
压缩列表
- 压缩列表实际上类似于一个数组,数组中的每一个元素都对应保存一个数据
- 压缩列表在表头有三个字段 zlbytes、zltail 和 zllen
- 分别表示列表长度、列表尾的偏移量和列表中的 entry 个数;压缩列表在表尾还有一个 zlend,表示列表结束。
- 当定位 第一个元素、最后一个元素时,复杂度为 O(1)、查找其他元素时,为 O(n)
跳表
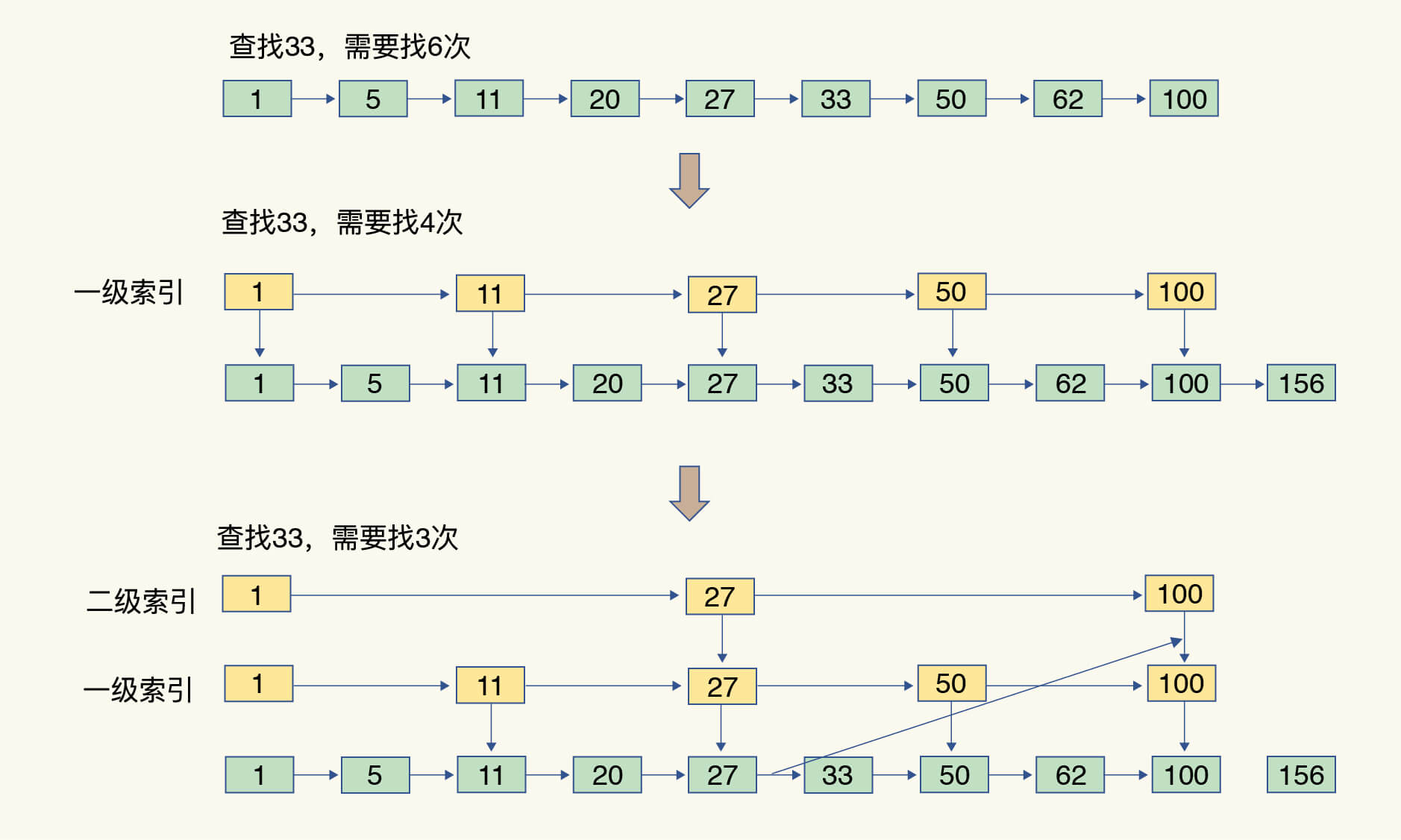
- 跳表在链表的基础上,增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位
- 为了提高查找速度,增加了一级索引:从第一个元素开始,每两个元素选一个出来作为索引。这些索引再通过指针指向原始的链表。
- 如果还想再快,可以再增加二级索引:从一级索引中,再抽取部分元素作为二级索引。例如,从一级索引中抽取 1、27、100 作为二级索引,二级索引指向一级索引
- 跳表的查找复杂度就是 O(logN)
复杂度
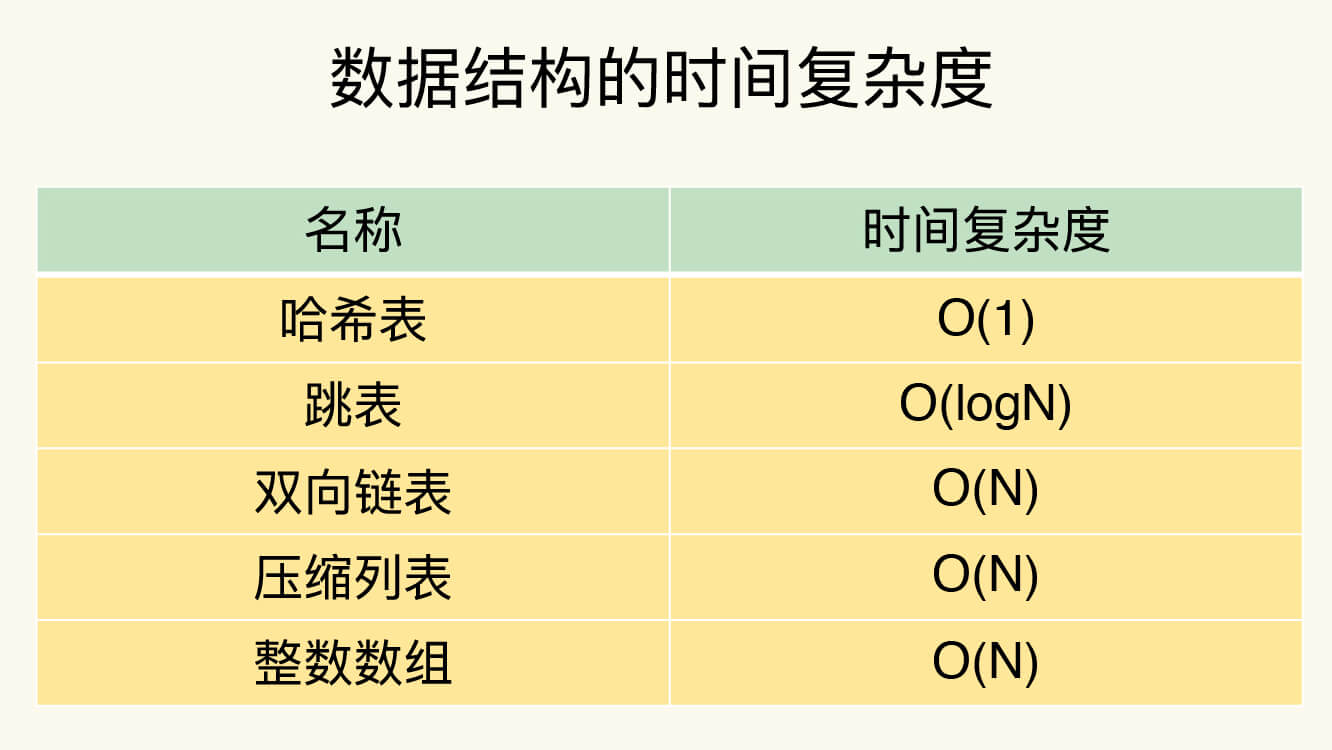
PS
- 常规情况下,数据操作复杂度与其数据结构有关,但有些数据结构在特殊情况下不同
- List 类型的 LPOP、RPOP、LPUSH、RPUSH 这四个操作是在列表的头尾增删元素,可以通过偏移量直接定位,所以它们的复杂度也只有 O(1)
参考
- 极客时间 « Redis核心技术与实战 » 专栏
文章作者 Xiang
上次更新 2021-05-30