MySQL InnoDB 对于 order by 的几种处理方式
文章目录
MySQL ORDER BY 的几种排序算法
- 表结构
|
|
全字段排序
|
|
说明
- 全字段排序相当于将要SELECT的、WHERE后的、要ORDER BY排序的字段,全部取出,存入内存或磁盘文件中进行排序
执行过程
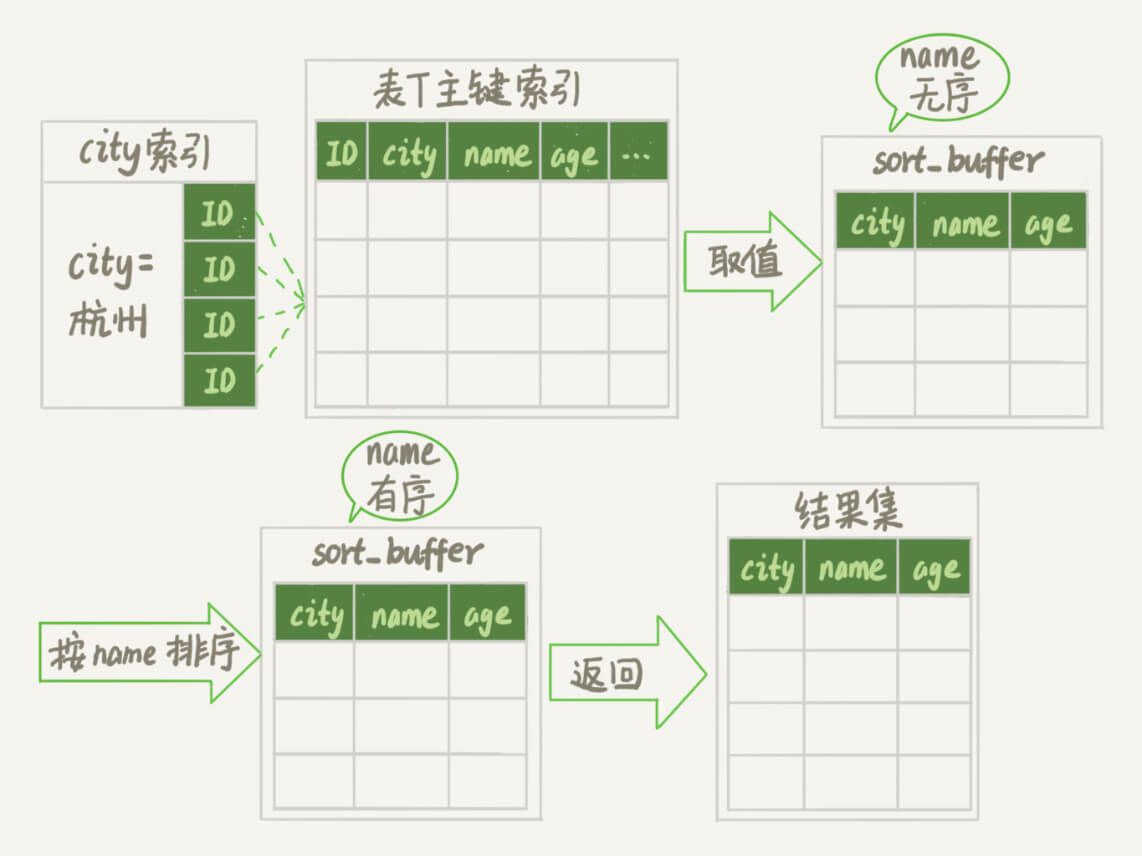
- 初始化 sort_buffer,确定放入 name、city、age 这三个字段;
- 从索引 city 找到第一个满足 city='山东省’条件的主键 id,也就是图中的 ID_X;
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到 city 的值不满足查询条件为止,对应的主键 id 也就是图中的 ID_Y;
- 对 sort_buffer 中的数据按照字段 name 做快速排序;
- 按照排序结果取前 10000 行返回给客户端。
判断方式
- 可通过 OPTIMIZER_TRACE 查看
- filesort_summary 中的 sort_mode 为 packed_additional_fields,则表示使用全字段排序
- chosen 为 false 则说明未使用优先队列排序算法(下文会介绍此算法)
|
|
rowid 排序
|
|
说明
- 全字段排序会将所有要返回的数据全部放入sort buffer中,然后再执行排序
- 如果查询字段过多,内存里能够同时放下的行数很少,要分成很多个磁盘临时文件,排序的性能会很差
- 当 MySQL 认为排序的单行长度过大时,MySQL会采用rowid算法进行排序
- 使用rowid算法进行排序,相对于全字段排序,会多一次 limit行数 的回表的开销
- 使用rowid的值由 max_length_for_sort_data 控制;当使用全字段排序写入临时表的字段长度超过 max_length_for_sort_data时,数据库会使用rowid排序
- 实际处理方式是只取where所需字段、排序所需字段及主键id进行排序,之后回表查询要返回的数据
执行过程
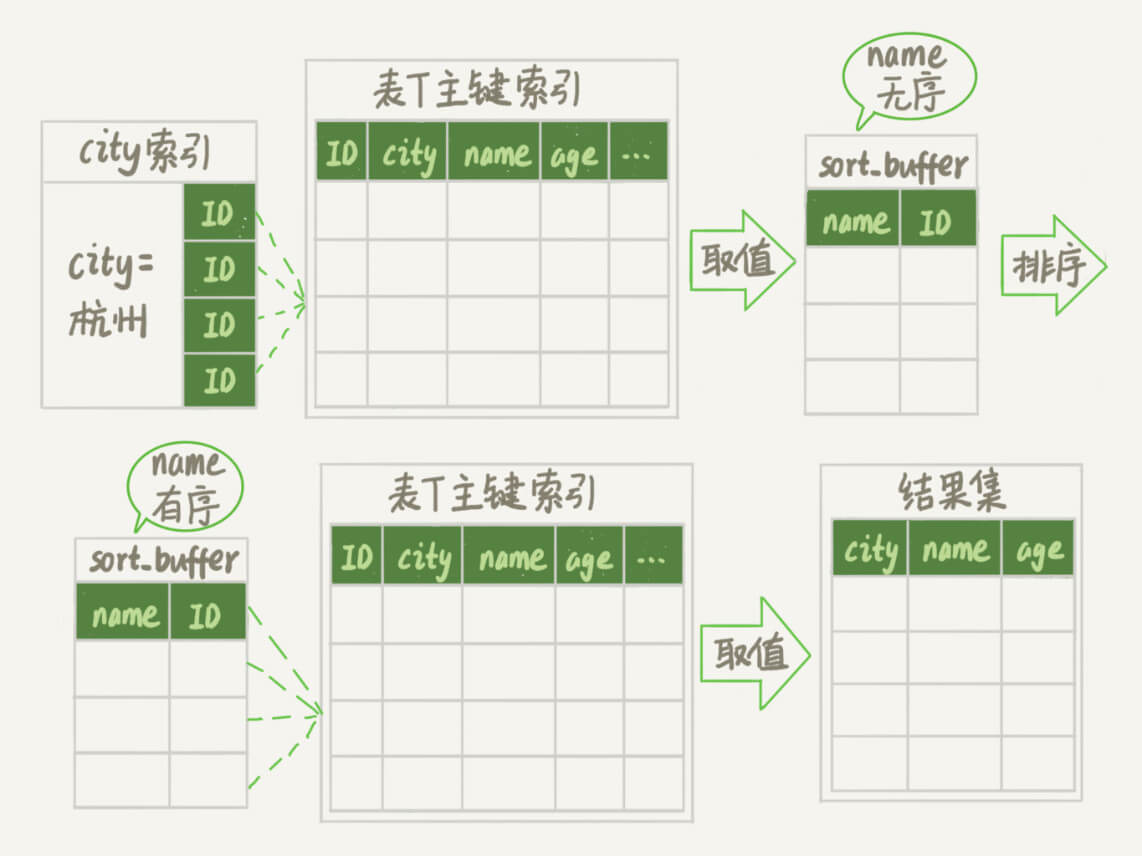
- 执行过程
- 初始化 sort_buffer,确定放入两个字段,即 name 和 id;
- 从索引 city 找到第一个满足 city='山东省’条件的主键 id,也就是图中的 ID_X;
- 到主键 id 索引取出整行,取 name、id 这两个字段,存入 sort_buffer 中;
- 从索引 city 取下一个记录的主键 id;
- 重复步骤 3、4 直到不满足 city='杭州’条件为止,也就是图中的 ID_Y;
- 对 sort_buffer 中的数据按照字段 name 进行排序;
- 遍历排序结果,取前 10000 行,并按照 id 的值回到原表中取出 city、name 和 age 三个字段返回给客户端。
判断方式
- 可通过 OPTIMIZER_TRACE 查看
- filesort_summary 中的 sort_mode 为 packed_additional_fields,则表示使用全字段排序
- chosen 为 true 则说明使用优先队列排序算法(下文会介绍此算法)
- 由于使用 rowid 算法,排序字段较少,排序时 sort_buffer_pool 的大小可以容纳 10000 行值,所以使用优先队列排序算法
|
|
优先队列排序算法
- 表结构
|
|
- 查询 sql
|
|
说明
- 当 limit 后数值不大时,InnoDB 并不会先进行取值
- 而是创建一个堆,先读入limit后指定数量的值,然后继续对符合条件的值进行比较,替换堆中的值
- 直至扫描完满足条件的值后,返回结果
- 如果 limit 过大,超过 sort_buffer_size ,则会忽略此算法(由于堆维护成本比数组大,不能用 行数 * 字段长度 的方式进行估算)
执行过程
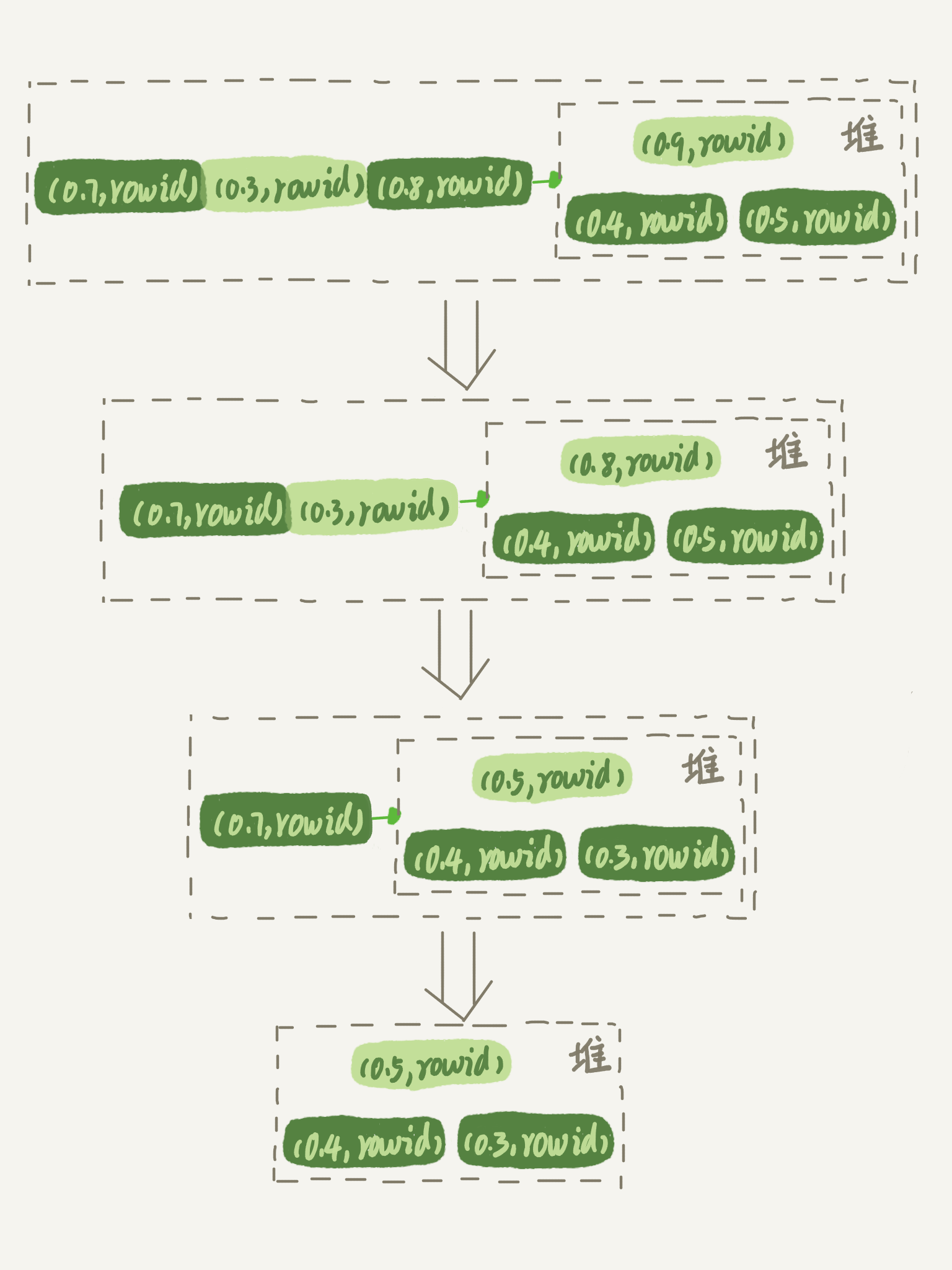
- 以取 3 行为例子
- 先取前三行,构造成一个堆
- 取下一个行 (R’,rowid’),跟当前堆里面最大的 R 比较,如果 R’小于 R,把这个 (R,rowid) 从堆中去掉,换成 (R’,rowid’)
- 重复第 2 步,直到第 10000 个 (R’,rowid’) 完成比较
判断方式
- 可通过 OPTIMIZER_TRACE
- 查看 filesort_priority_queue_optimization 中的 chosen=true 表示使用了优先队列排序算法
|
|
使用 OPTIMIZER_TRACE 判断 SQL 的具体执行过程
|
|
ORDER BY 优化思路
通过复合索引获取有序数据避免 sort_buffer
|
|
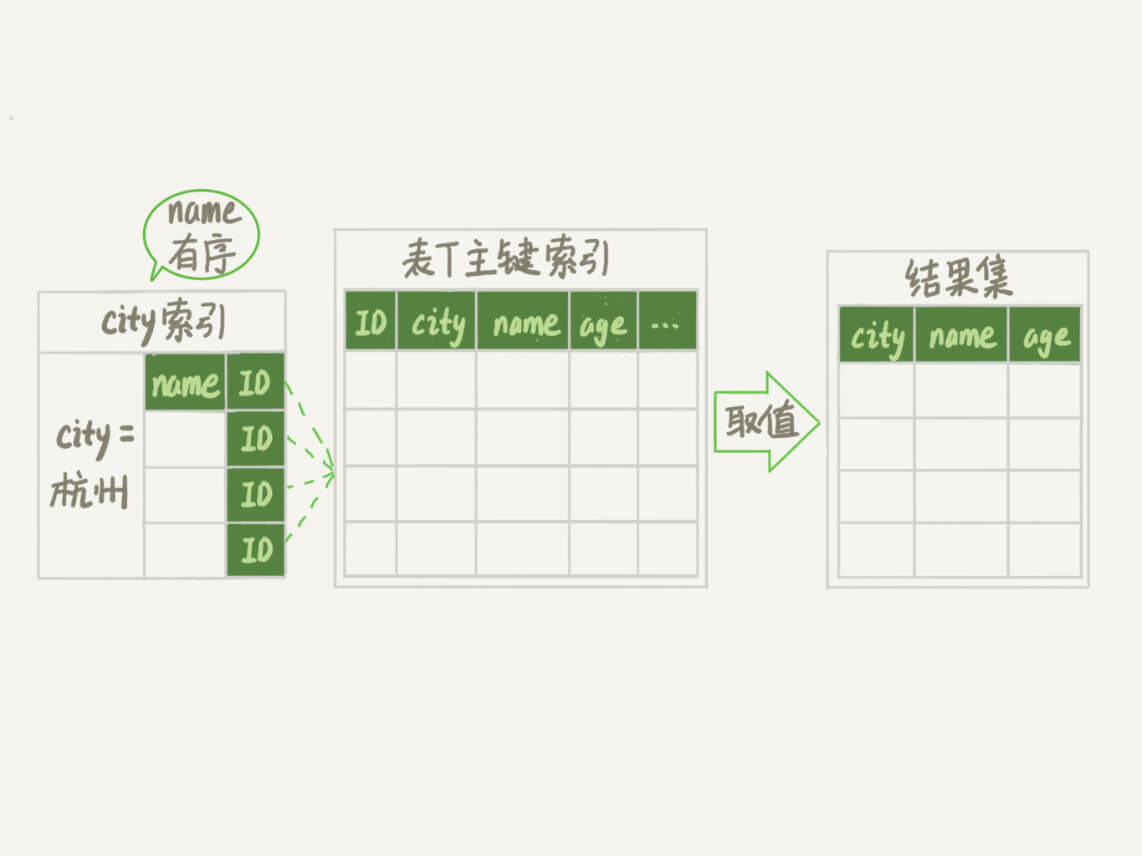
- 增加索引后执行过程
- 从索引 (city,name) 找到第一个满足 city='山东省’条件的主键 id;
- 到主键 id 索引取出整行,取 name、city、age 三个字段的值,作为结果集的一部分直接返回;
- 从索引 (city,name) 取下一个记录主键 id;
- 重复步骤 2、3,直到查到第 10000 条记录,或者是不满足 city='山东省’条件时循环结束
使用覆盖索引
|
|
- 增加索引后执行过程
- 从索引 (city,name,age) 找到第一个满足 city='山东省’条件的记录,取出其中的 city、name 和 age 这三个字段的值,作为结果集的一部分直接返回;
- 从索引 (city,name,age) 取下一个记录,同样取出这三个字段的值,作为结果集的一部分直接返回;
- 重复执行步骤 2,直到查到第 10000 条记录,或者是不满足 city='山东省’条件时循环结束。
参考
- 极客时间 丁奇 « MySQL实战45讲 » 专栏
文章作者 Xiang
上次更新 2021-04-28